This paper proposes a Momentum Contrast (MoCo) method for unsupervised visual representation learning. Unlike previous methods, MoCo treats contrastive learning as a dictionary loolup task. The framework of MoCo is outlined as follows:
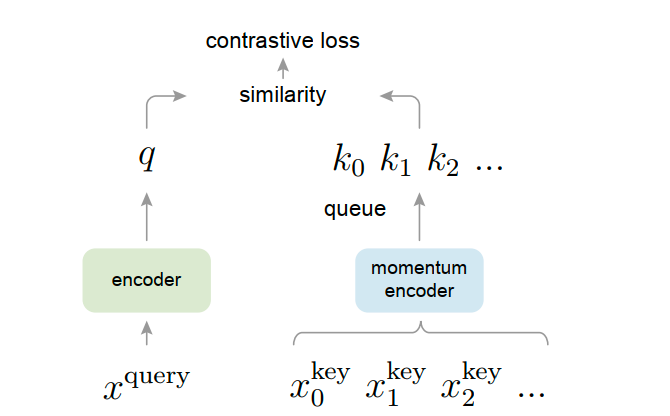 Moco trains the visual representation encoder by matching the encoder query $q$ with keys encoded in a dictionary. Notably, the encoder is optimized via backpropagation, while the momentum encoder is optimized using the momentum update. The momentum update is defined as follows:
Moco trains the visual representation encoder by matching the encoder query $q$ with keys encoded in a dictionary. Notably, the encoder is optimized via backpropagation, while the momentum encoder is optimized using the momentum update. The momentum update is defined as follows:
where $\theta_k$ represents the parameters of the momentum encoder and $\theta_q$ represents the parameters of the encoder. The update to the momentum encoder should be gradual. Experimental results show that rapidly changing encoders lead to suboptimal results. They hypothesize that this is because rapidly changing encoders reduce the consistency of key representations. Therefore, in the experiments, they set m between 0.99 and 0.9999.
References
He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738).