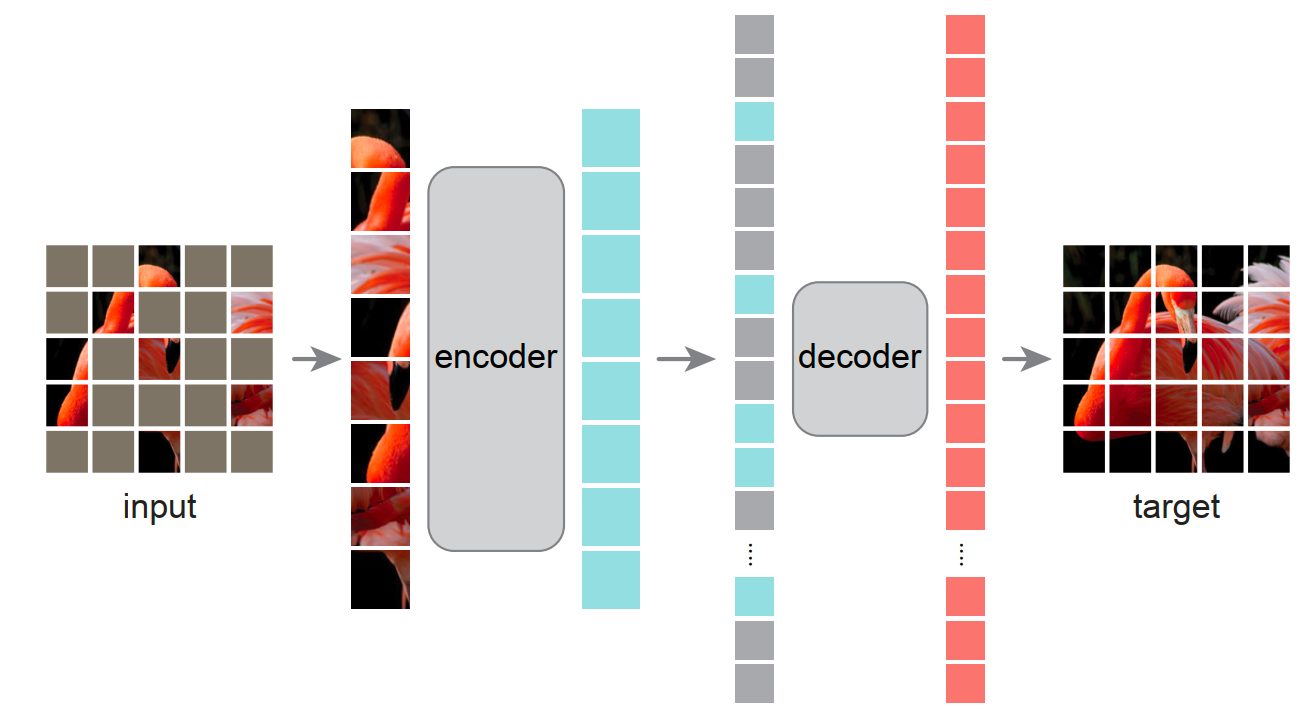
This paper proposes a scalable self-supervised learning method-Masked Autoencoders (MAE) for computer vision. MAE reconstructs the missing pixels from randomly masked images. MAE has two key design elements.
Firstly, the encoder-decoder architecture is asymmetric. The encoder processes only the visible parts of the image, ignoring the masked pixels. However, the decoder’s input includes not only the encoded visiable pixels but also the masked tokens. Specifically, the masked tokens are shared, learnable vectors that represent the missing pixels to predicted. Notably, the decoder is lightweight.
Secondly, only a high proportion of masked images (e.g. 75%) can generate a non-trivial and meaningful self-supervised task.
References
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 16000-16009).