Before introducing this work, I will first present the Real-time explainer (RTX) framework. RTX is a one-feed-forward explainer that can generate model explanations more efficiently. A major limitation of existing RTX approaches is their reliance on a large number of explanation labels. In my view, RTX is a neural network that generates explanations but like other domains, it also requires substantial data for training.
However, due to limited computational resources and constrained human efforts. accurate explanation labels are difficult to obtain. To address this issue, thie paper proposes the Contrastive Real-Time eXplanation (CoRTX) method. CoRTX trains an encoder using contrastive learning to learn latent explanations in a self-supervised manner, thereby allevating the challenge of data scarcity.
The overview of the CoRTX framework is as follows:
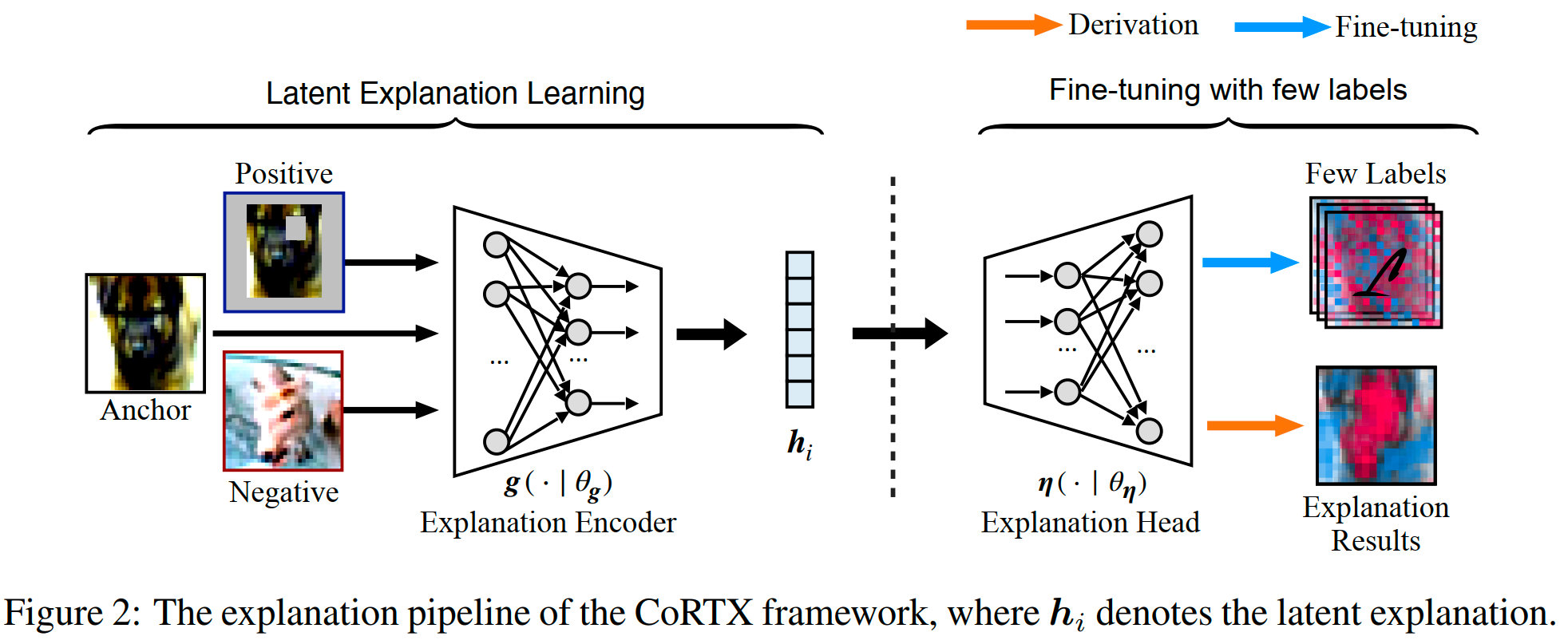
Explanation-oriented Data Augmentation: The intuition behind data augmentation is that similar data should have similar explanations. In this paper, $\mathbf{x}^{+}$ is the positive instance for the anchor data instance $\mathbf{x}$. $\mathbf{x}^{+}$ is generated by perturbating $\mathbf{x}$, and the explanations of $\mathbf{x}^{+}$ and $\mathbf{x}$ should be similar.
$$ \mathbf{x}^{+} = \mathbf{S}_i \odot \boldsymbol{x}+\left(\mathbf{1}-\mathbf{S}_i\right) \odot \boldsymbol{x}_r, \mathbf{S}_i \sim \mathcal{B}(M, \lambda), 1 \leq i \leq m, $$where $\mathbf{S}_{i}$ is sampled from an M-dim binomial distribution, and $\mathbf{x}_r$ is the reference value.
Contrastive Loss: Let $\mathbf{h}_i = g(x_i | \theta_g)$, $\tilde{\mathbf{h}}^{+}_{i} = g(\tilde{\mathbf{x}}^{+}_i | \theta_g)$ be the latent explanation of the positive pair, and $\mathbf{h}_i$, $\mathbf{h}_j = g(\mathbf{x}_j | \theta_g)$ be the latent explanation for a negative pair.
$$ \mathcal{L}_g=-\log \frac{\exp \left(\boldsymbol{h}_i \cdot \tilde{\boldsymbol{h}}_i^{+} / \tau\right)}{\sum_{j=1}^N \exp \left(\boldsymbol{h}_i \cdot \boldsymbol{h}_j / \tau\right)} $$Fine-tuning the Explanation Head: They leverage a small number of explanation labels to fine-tune the explanation head $\mathbf{\eta}(\cdot|\theta_{\eta})$.
They designed two tasks along with their corresponding loss functions: (1) Feature Attribution Task: this task aims to test the explanation performance on feature attribution. (2) Feature Importance Ranking Task: this task aims to evaluate the explanation on feature ranking index.
CODE: The pseudocode is as follows:
for epoch in range(n_epoch):
# Train the encoder for one epoch.
for data_i in data_loader:
optimize encoder(data_i)
if epoch % 5 == 0:
# Train the explanation head until convergence.
for epoch_i in range(n_explanation_epoch)
optimize explanation_head(encoder(data_i))
References
Chuang, Y. N., Wang, G., Yang, F., Zhou, Q., Tripathi, P., Cai, X., & Hu, X. (2023). Cortx: Contrastive framework for real-time explanation. arXiv preprint arXiv:2303.02794.