When applying the Integrated Gradients method to language models, it constructs an integral path by modifying each word in a sentence simultneously. As a result, the interpolated sentences either lack clear meaning or differ significantly from the original sentence.
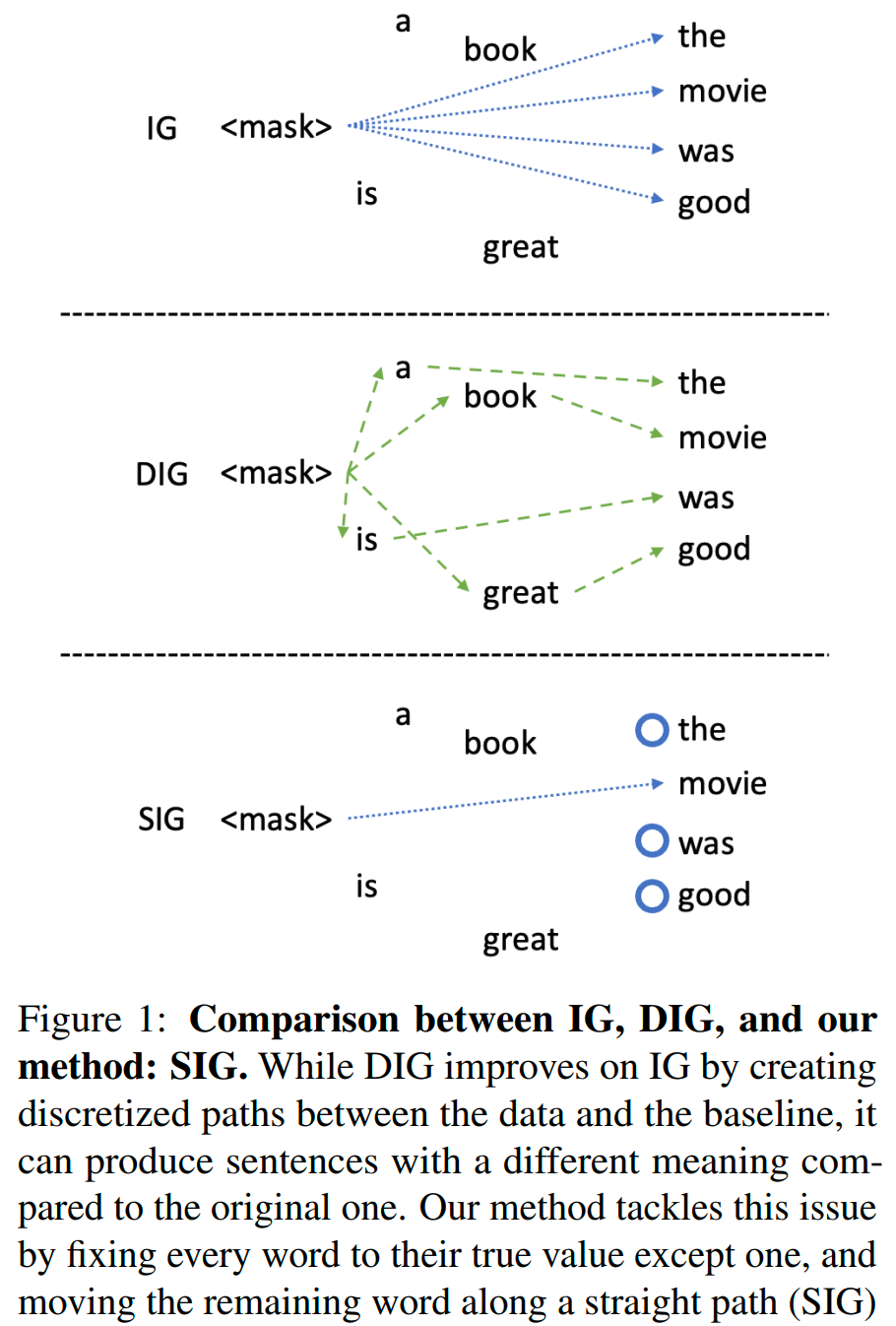
Based on my understanding, rather than constructing a single integral path for all words in a sentence, this method constructs an integral path for each word individually.
Assuming that the original sentences is $\mathbf{x} = \left(\mathbf{x}_1, \ldots, \mathbf{x}_i, \ldots, \mathbf{x}_m\right)$, the main process is as follows:
Step 1: Construct a baseline $\overline{\mathbf{x}}^i$ for each word $\mathbf{x}^i$.
$$ \overline{\mathbf{x}}^i=\left(\mathbf{x}_1, \ldots,<\text { mask }>, \ldots, \mathbf{x}_m\right) $$Step 2: For each word $\mathbf{x}_i$ and feature $j$, define the Sequential Integrated Gradients $SIG$ as follows:
$$ \operatorname{SIG}_{i j}(\mathbf{x}):= \left(x_{i j}-\bar{x}_{i j}\right) \times \int_0^1 \frac{\partial \mathrm{~F}\left(\overline{\mathbf{x}}^i+\alpha \times\left(\mathbf{x}-\overline{\mathbf{x}}^i\right)\right)}{\partial x_{i j}} d \alpha $$Step 3: Compute the overall contribution of a word by summing over the feature dimension $j$, and normalising the result:
$$ \operatorname{SIG}_i(\mathbf{x}):=\frac{\sum_j \operatorname{SIG}_{i j}}{\|\mathrm{SIG}\|} $$Reference
ACL findings 2023 Sequential Integrated Gradients: a simple but effective method for explaining language models